사실이 아니라 공부한 내용과 생각을 정리한 글입니다. 언제든 가르침을 주신다면 감사하겠습니다.
기술에 대한 필요성
spring mvc 환경에선 하나의 요청당 하나의 스레드가 할당되어 요청을 처리하게 된다.
이는 기본적으로 모든 요청을 동기적(순차적)으로 처리한다는 의미이다.
모든 요청을 동기적으로 처리하는 방식은 인간이 가장 이해하기 쉬운 방식이기 때문에, 이 방식으로 시스템을 구성하고 코드를 작성하는 것은 코드에 대한 가독성과 유지보수성을 좋게 유지할 수 있는 선택지가 된다.
따라서 대부분의 상황에서 이 방식은 좋은 선택지가 된다.(심플이즈베스트..)
하지만 특정 상황에서 트레이드오프를 해야 할 수도 있다.
예를 들어 하나의 요청에서 처리해야 하는 작업이 외부 api를 10번 호출해야 하는 일이고, 각각의 api 호출이 1초가 걸리는 상황이라고 가정해 보자.
이를 단순 동기적 방식으로 처리하게 되면 한 번의 요청을 처리하는데 최소 10초가 소요된다.
해당 api 가 사용자와 맞닿아 있는 api 라면, 사용자 입장에서 해당 api를 호출할 때 마다 10초를 기다리는건 너무 큰 불편함일 수 있다.
사용자와 맞닿아 있는 api 가 아니더라도, 해당 api 를 호출한 다른 시스템이 매번 10초 동안 기다려야 하는 것도 너무 큰 손실일 수 있다.
이러한 상황에선 유지보수성을 낮추더라도 10초라는 시간을 단축하는 게 더 중요할 수 있다.
이번 글에서는 1초가 걸리는 외부 api를 10번 호출하는 작업을 예시로 시스템 자원과 성능, 코드에 대한 유지보수성 관점에서 TaskExecutor & Coroutine & Webclient 기술을 소개 및 비교해보려 한다.
(예시 코드는 https://github.com/rnjstjdgh/api-call-test 에 있습니다.)
테스트를 위한 Mock api server
@RestController
class TestController {
@GetMapping("/test/{sleep}/{idx}")
fun test(
@PathVariable("sleep") sleep: Long,
@PathVariable("idx") idx: Long,
): ResponseEntity<String> {
Thread.sleep(sleep)
return ResponseEntity.ok("result${idx}")
}
}sleep millisecond 가 걸리는 외부 api를 제공하기 위한 mock api server이다.
api 요청 path에 sleep과 idx를 path variable로 넘겨주면 sleep millisecond 만큼 대기하다가 "result${idx}"를 응답하는 api를 제공한다.
해당 api endpoint를 제공하는 서버를 localhost:8081로 기동한다.
가장 단순한 동기코드
@Service
@FeignClient(
contextId = "testFeignService",
name = "test",
url = "\${test.api.url}", // localhost:8081 로 설정
configuration = [FeignConfig::class]
)
interface FeignService {
@GetMapping("/test/{sleep}/{idx}")
fun testCall(
@PathVariable("sleep") sleep: Long,
@PathVariable("idx") idx: Long,
): String
}우선 mock api server를 호출하기 위한 fegin client를 생성한다.(fegin client 는 동기식으로 api를 호출한다.)
@RestController
class NormalTestController(
private val feignService: FeignService,
) {
@GetMapping("/test/normal/{sleep}")
fun `일반적인동기코드`(
@PathVariable("sleep") sleep: Long,
): ResponseEntity<List<String>> {
println("호출전: ${LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))}")
val resultList = (1..10).map {
feignService.testCall(sleep, it.toLong())
}
println("호출후: ${LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))}")
return ResponseEntity.ok(resultList)
}
}위에서 만든 fegin client 를 활용해 sleep millisecond 가 소요되는 api 를 10번 호출하는 api이다.
요청에 할당된 스레드가 동기적으로 모든 작업을 처리하기 때문에 , sleep을 1000으로 설정하고 해당 api를 호출하면 약 10초 후 응답을 받을 수 있다.


이제부터 TaskExecutor & Coroutine & Webclient 기술을 사용해 이를 개선해 보자.
TaskExecutor를 사용한 비동기 코드
위 문제상황을 해결하기 위해 java에서 과거에 가장 많이 사용했던 방식은, 별도의 스레드풀을 정의하고 해당 스레드풀에 비동기적으로 작업을 할당하는 방식이었다.
1초가 걸리는 작업을 10번 수행할 때, 하나의 스레드에서 이 작업을 다 처리하는 게 아니라 10개의 스레드에 작업을 분배하여 동시에 처리하도록 구성하고 이를 합쳐 응답을 만드는 개념이다.
이렇게 하면 하나의 스레드에서 10초가 걸리는 작업을 10개의 스레드에 분산시켜 전체 작업을 1초 만에 끝마칠 수 있다.

아래 예시코드를 보자.
@Configuration
@EnableAsync
class AsyncConfig {
@Bean
@Primary
fun taskExecutor(): Executor {
return ThreadPoolTaskExecutor()
.apply {
corePoolSize = 10
maxPoolSize = 10
queueCapacity = 10
setThreadNamePrefix("taskExecutor")
}
}
}작업을 할당할 별도의 스레드풀을 정의한다.(설정값의 상세 설명은 생략한다...)
@RestController
class AsyncTestController(
private val feignService: FeignService,
private val executor: Executor,
) {
@GetMapping("/test/task_executor/{sleep}")
fun `TaskExecutor 기반 비동기코드`(
@PathVariable("sleep") sleep: Long,
): ResponseEntity<List<String>> {
println("호출전: ${LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))}")
val resultList = (1..10).map {
CompletableFuture.supplyAsync({ feignService.testCall(sleep, it.toLong()) }, executor)
}.map { it.get() }
println("호출후: ${LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))}")
return ResponseEntity.ok(resultList)
}
}비동기 스레드풀을 활용하기 위한 하나의 방법으로 completableFuture를 사용했다.
요청을 받은 메인스레드에서 10개의 비동기 작업을 만들어서 비동기 스레드풀에 던지고 결과를 동기적으로 취합하고 있다.
앞서 언급한 데로, 1초가 소요되는 10번의 api call을 10개의 스레드에서 나눠서 처리하고 있기 때문에 총 소요시간은 약 1초로 10배 정도 감소하게 된다.


10초가 걸리던 하나의 작업을 10개의 세부 작업으로 분해하고, 비동기적으로 스레드에 작업을 할당함으로써 전체 소요시간이 획기적으로 감소한 것을 확인할 수 있었다.
하지만 이 작업을 처리하는데 소요된 시간 관점이 아니라 사용된 자원 관점에서 보면 1개의 스레드가 처리하던 작업을 11개의 스레드가 처리하고 있다.
만약 해당 작업을 최소한의 스레드로 처리해야 한다면 어떻게 될까? 혹은 미리 정의한 비동기 스레드풀이 감당하지 못할 정도의 트래픽이 몰리게 되면 어떻게 될까?
이를 시뮬레이션하기 위해 스레드풀의 스레드 수를 1개로 제한해서 해당 작업을 다시 돌려보았다.
@Configuration
@EnableAsync
class AsyncConfig {
@Bean
@Primary
fun cherryTaskExecutor(): Executor {
return ThreadPoolTaskExecutor()
.apply {
corePoolSize = 1 // 스레드 1개로 제한
maxPoolSize = 1 // 스레드 1개로 제한
queueCapacity = 10
setThreadNamePrefix("taskExecutor")
}
}
}
비동기 스레드풀의 스레드 수를 1개로 설정하니 소요시간이 10초가 되었다.
10개의 작업을 비동기 스레드풀에 던졌으나 가용 스레드 개수가 1개이기 때문에 결국 동시에 처리하지 못하고 순차적으로 처리하게 된 것이다.
이를 통해 스레드풀을 활용한 방식도 해당 스레드풀이 감당할 수 없는 부하가 몰리는 시점부터 스레드풀에서 스레드를 얻기 위한 대기가 발생하고, 이로인한 급격한 성능저하를 유발할 가능성이 있다는 것을 알 수 있다.
혹자는 스레드풀의 스레드 수를 늘리면 되지 않냐고 할 수 있다.
하지만 스레드를 생성하고 유지하는 것 자체가 메모리를 많이 잡아먹고 문맥교환이 발생하여 많은 리소스를 잡아먹기 때문에 일정 수준 이상으로 스레드 수를 늘릴 수는 없다.
코루틴을 사용한 비동기 코드
지금까지 비동기 기술의 조상 격인 CompletableFuture를 알아봤다면, 이제부터 요즘 핫한 코루틴에 대해 알아보자.
이 기술도 근본적으로는 위에서 살펴봤던 CompletableFuture와 유사한 부분이 있다.
1개의 오래 걸리는 작업을 세부 작업으로 분할하고 각각의 작업단위에 코루틴이라는 이름을 부여한다.
각각의 코루틴이 미리 정의해 둔 비동기 스레드풀에 의해 실행된다는 점이 위에서 살펴봤던 CompletableFuture와 비슷한 면이다.
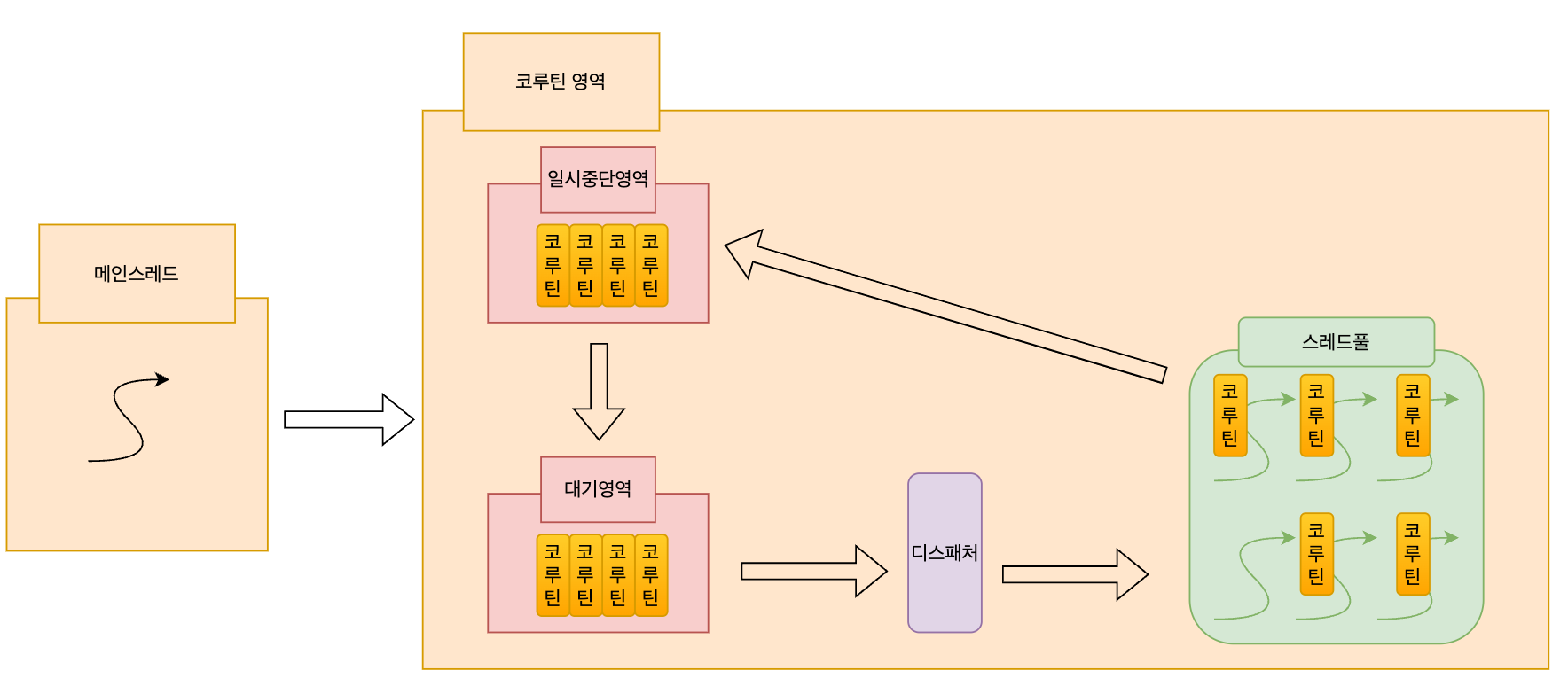
차이가 있다면 코루틴은 일시중단과 재개를 통한 협력적 멀티태스킹을 기반으로 동작한다.
메인스레드에서 수행할 작업을 여러 코루틴으로 분할해 코루틴 영역에서 수행하게 되는데, 각각의 코루틴은 디스패쳐를 통해 스레드에 할당되어 작업을 수행한다. 작업을 수행하던 코루틴은 일시중단 지점을 만나면 스스로 스레드로부터 벗어나 유휴 상태가 된다.(비선점) 이렇게 스스로 스레드로부터 벗어남으로써 해당 스레드는 다른 코루틴을 처리할 수 있는 상태가 된다.
하나의 루틴에서 IO-Bocking과 같은 일이 발생하는 지점에서 일시중단 포인트를 잘 잡는다면 스레드가 IO로 인해 Blocking 되는 상황을 만들지 않을 수 있고 이러한 방식을 통해 스레드를 조금 더 효과적으로 사용할 수 있다.
코루틴을 활용한 샘플 코드를 살펴보자
@RestController
class CoroutineTestController(
private val feignService: FeignService,
) {
@GetMapping("/test/coroutine/{sleep}")
fun `Coroutine 기반 비동기코드`(
@PathVariable("sleep") sleep: Long,
): ResponseEntity<List<String>> {
println("호출전: ${LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))}")
val resultList = runBlocking(newFixedThreadPoolContext(10, "coroutine-thread")) {
(1..10).map {
async { feignService.testCall(sleep, it.toLong()) }
}.awaitAll()
}
println("호출후: ${LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))}")
return ResponseEntity.ok(resultList)
}
}CompletableFuture를 활용한 방식과 유사하게 요청을 받은 메인스레드에서 10개의 코루틴을 만들어서 코루틴 영역으로 던지고 동기적으로 결과를 취합해 응답한다.
newFixedThreadPoolContext(10, "coroutine-thread")에 주목해 보자.
지금은 10개의 코루틴을 수행할 코루틴 영역에 10개의 스레드가 있는 스레드 풀을 할당했고 이 상태에서 API을 호출하면 결과는 아래와 같다.

1초의 소요시간이 걸렸다.
여기서 스레드풀의 스레드 수를 1개로 제한하면 어떻게 될까?
newFixedThreadPoolContext(1, "coroutine-thread")로 수정 후 다시 실행해 보았다.

10초의 소요시간이 걸렸다.
스레드풀에 할당된 스레드 개수에 따른 응답시간이 completableFuture를 사용했을 때와 동일하게 나온 것을 확인할 수 있다.
이러한 현상은 앞서 언급했던 completableFuture와 coroutine 의 공통점에서 기인한다.
결국 두 가지 기술 다 비동기 스레드풀에 작업을 할당하는 방식이고 작업 중인 스레드가 Blocking 되는 지점이 있다면(코루틴의 경우 이 Blocking 지점에서 일시중단하지 않는다면) 부하가 몰렸을 때 급격한 성능저하를 유발할 수 있다.
결국 스레드가 IO로 인해 Blocking 되는 것이 근본적인 문제다.
Weclient를 사용한 이벤트 루프 기반 코드
IO가 발생하는 동안 스레드를 Blocking 하지 않기 위한 방법으로 event loop 기반의 webclient 기술을 활용할 수 있다.
event loop 기반 기술도 결국 스레드풀을 활용하고 거기에 작업을 할당하는 것은 동일하다.
하지만, 한번 작업이 할당된 스레드는 IO 하는 시점에 Blocking 되지 않고 다시 스레드풀에 반환되어 다른 처리를 할 수 있는 상태가 된다.(Non-Blocking) 그리고 이후 IO가 완료된 시점에 event를 받아 다시 스레드가 할당되고 이후 작업을 처리하게 된다.
즉 IO로 인한 스레드 Blocking이 없다.
바로 예시코드를 살펴보자
@Configuration
class WebClientConfig {
companion object {
val THREADS = 1
val THREADFACTORY: BasicThreadFactory = BasicThreadFactory.Builder()
.namingPattern("HttpThread-%d")
.daemon(true)
.priority(Thread.MAX_PRIORITY)
.build()
val EXECUTOR = ThreadPoolExecutor(
THREADS,
THREADS,
0L,
TimeUnit.MILLISECONDS,
LinkedBlockingQueue(),
THREADFACTORY,
ThreadPoolExecutor.AbortPolicy()
)
val RESOURCE = NioEventLoopGroup(THREADS, EXECUTOR)
}
@Bean(name = ["webClient"])
fun buildWebClient(): WebClient {
val provider = ConnectionProvider.builder("custom-provider")
.maxConnections(100)
.maxIdleTime(Duration.ofSeconds(58))
.maxLifeTime(Duration.ofSeconds(58))
.pendingAcquireTimeout(Duration.ofMillis(5000))
.pendingAcquireMaxCount(-1)
.evictInBackground(Duration.ofSeconds(30))
.lifo()
.metrics(false)
.build()
val reactorResourceFactory = ReactorResourceFactory().apply {
connectionProvider = provider
loopResources = LoopResources { RESOURCE }
isUseGlobalResources = false
}
return WebClient.builder()
.baseUrl("http://localhost:8081")
.clientConnector(ReactorClientHttpConnector(reactorResourceFactory) { httpClient ->
httpClient.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 5000)
.responseTimeout(Duration.ofMillis(5000))
.doOnConnected { conn ->
conn.addHandlerLast(ReadTimeoutHandler(5000, TimeUnit.MILLISECONDS))
.addHandlerLast(WriteTimeoutHandler(5000, TimeUnit.MILLISECONDS))
}
})
.build()
}
}WebClient 빈을 만드는 코드다.
코드가 다소 복잡할 수 있지만 핵심적인 부분만 차분히 살펴보자.
val THREADS = 1
val THREADFACTORY: BasicThreadFactory = BasicThreadFactory.Builder()
.namingPattern("HttpThread-%d")
.daemon(true)
.priority(Thread.MAX_PRIORITY)
.build()
val EXECUTOR = ThreadPoolExecutor(
THREADS,
THREADS,
0L,
TimeUnit.MILLISECONDS,
LinkedBlockingQueue(),
THREADFACTORY,
ThreadPoolExecutor.AbortPolicy()
)
val RESOURCE = NioEventLoopGroup(THREADS, EXECUTOR)webClient를 만들 때 사용할 이벤트 그룹을 생성하는 코드인데, Executor를 넣어주고 있다.
Executor는 스레드풀을 지정할 수 있고 해당 스레드풀의 스레드 개수는 1개로 세팅되어 있다.
즉, webclient를 통한 api 호출을 위해 사용되는 스레드는 1개로 지정되어 있다.
이렇게 만들어진 webclient를 주입받아 작업을 수행하는 코드를 살펴보자.
@RestController
class WebClientTestController(
private val webClient: WebClient
) {
@GetMapping("/test/webclient/non-blocking/{sleep}")
fun `webclient 기반 코드(non-blocking)`(
@PathVariable("sleep") sleep: Long,
): ResponseEntity<List<String?>> {
println("호출전: ${LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))}")
val resultList = Flux.merge((1..10).map {
webClientCall(sleep, it)
}).toIterable().toList()
println("호출후: ${LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))}")
return ResponseEntity.ok(resultList)
}
private fun webClientCall(
sleep: Long,
idx: Int,
): Mono<String?> {
return webClient.get()
.uri("/test/$sleep/$idx")
.retrieve()
.bodyToMono(String::class.java)
}
}앞선 예시와 유사하게 요청을 받은 메인스레드에서 1초가 소요되는 외부 api 호출을 10번 수행한다.
차이는 fegin을 활용하는 것 대신 webclient를 사용했다.
해당 코드를 수행하고 결과를 확인해 보자.
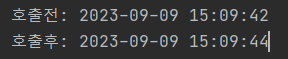
2초가 소요되었다.
webclient에 할당한 스레드는 고작 1개인데 2초 만에 10개의 api 호출을 모두 처리한 것이다.
이는 지금까지 살펴봤던 예시 중에 가장 적은 자원을 활용해 가장 높은 효율을 낸 결과이다.
이런 식으로 IO-Blocking 이 있는 작업의 경우 이벤트 루프 기반의 기술을 활용하면 성능적인 이익을 크게 얻어갈 수 있다.
하지만 이벤트 루프 기반의 기술은 기술 자체의 난도가 높고 작성되는 코드도 절차지향적이지 않다.
즉, 코드의 유지보수성 측면에서 기존 방식에 비해 단점이 많다.
결론
지금까지 1초가 걸리는 외부 api를 10번 호출하는 예시를 기반으로 시스템 자원과 성능, 코드 유지보수성 관점에서 가장 기본적인 동기 코드에서부터 이벤트 루프를 활용한 webclient까지 살펴보았다.
가장 기본적인 동기 코드는 가장 단순한 코드이지만 자원과 성능 관점에서 매우 한계가 있었다.
TaskExecutor 와 Coroutine 은 스레드풀에 작업을 던지는 방식으로서, 가장 단순한 동기 코드에 비해 성능을 향상할 수 있었지만 시스템 자원 관점에서 더 많은 스레드를 사용해야 했고, 각각의 세부 작업에 IO Blocking 이 있을 시 많은 스레드가 아무일도 하지않고 대기하는 일이 발생할 수 있었다.
IO Blocking 이 많은 작업의 경우 WebClient 와 같은 Non-Blocking 기술을 활용할 수 있었다.
하지만 이러한 Non-Blocking 기술은 기술적 난이도가 높고 코드의 유지보수성을 낮춘다는 단점이 있었다.
다음 글에서는 동일 예제를 가지고 Webclient 와 같은 Reactive stack 과 Coroutine 을 섞어 최소한의 자원으로 성능을 끌어 올리면서도 코드의 유지보수성을 유지하는 방법에 대해 다룬다.
그리고 java 21 에 추가된 virtual thread 에 대해서 짧게 다뤄보려 한다.
'java > thread(동시성)' 카테고리의 다른 글
| API 호출 관점에서 WebClient 와 Coroutine 조합해보기 (0) | 2024.01.30 |
|---|---|
| 스레드 block 관점에서 Webflux Map vs Flatmap 비교 (0) | 2023.10.02 |
| 비동기 & 논블러킹 의미 분석 (0) | 2022.08.11 |
| [Udemy: Java Multithreading, Concurrency & Performance Optimization] Motivation (0) | 2021.11.25 |


댓글